Why I am considering Rust over C++ for browser physics in WebAssembly
Nikos Katsikanis - April 27, 2026
I started with C++ for a small civil engineering stress demo, but I am now considering Rust because a browser teaching aid rewards safety, clear data flow, and small focused calculation kernels more than legacy reach.
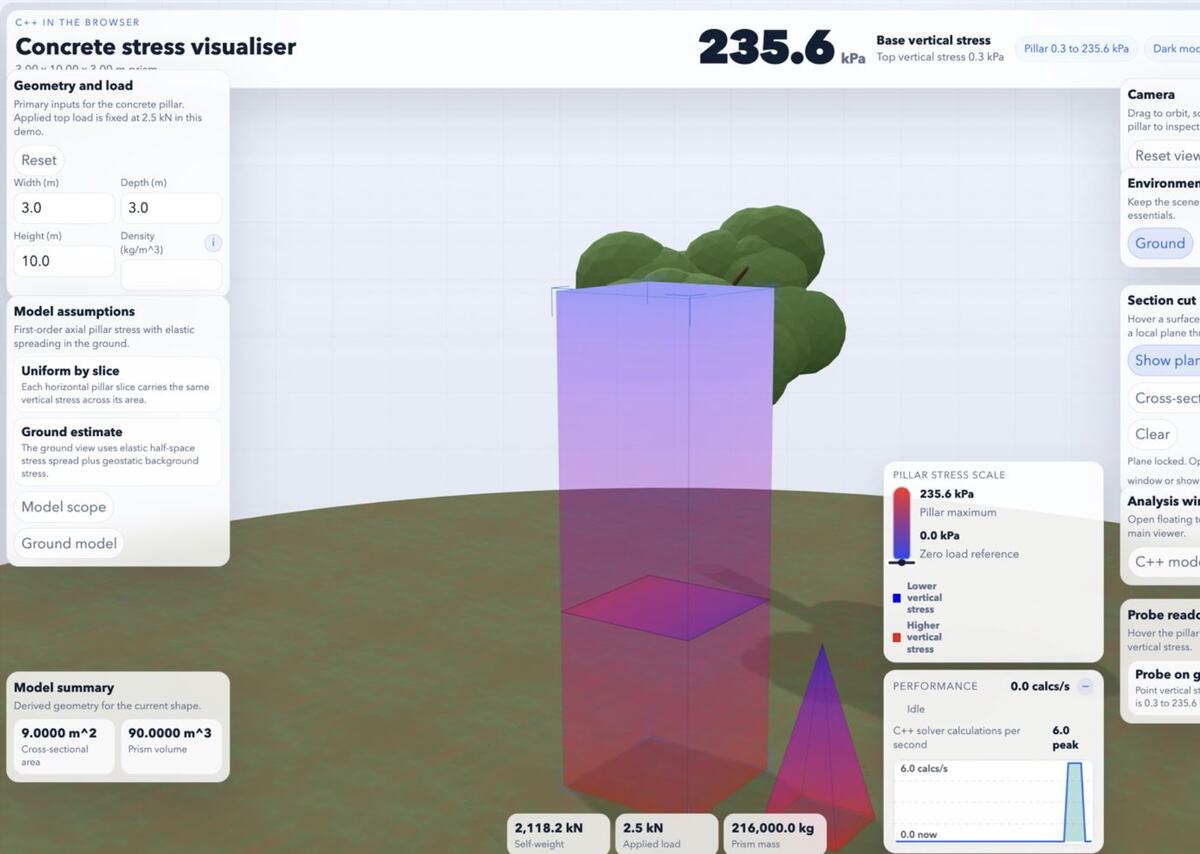
I have been experimenting with a small civil engineering calculation: a concrete prism, a ground domain, self-weight, applied load, and a sampled stress field under the footing. The first version was in C++ and exported through WebAssembly so I could run the calculation in the browser.
The goal is not an industrial solver. It is a website teaching aid and a self-learning tool. I want to move sliders, sample a stress plane, and help someone see how the numbers change. That changes the language decision. I do not only care about peak speed. I care about correctness, easy iteration, small downloads, and whether the code stays readable after I add more physics.
My short answer: if I were porting a mature C++ solver or a library-heavy desktop project, I would stay with C++. For a greenfield browser physics core, I am leaning Rust.
Why C++ is still a serious option
C++ has the strongest argument when I care about ecosystem gravity. It has decades of numerical code, physics engines, geometry libraries, examples, and engineers who already know the stack. If I needed to reuse established native code, C++ would be the pragmatic route.
The browser story is also mature. Emscripten is a complete C and C++ toolchain for WebAssembly, and Mozilla documents the C/C++ path as a normal way to compile code for the browser. That matters. I do not want a teaching tool to become a tooling research project.
C++ also has a stronger hiring story in many engineering domains. If the calculation grows toward native desktop use, embedded use, or existing engineering packages, C++ keeps more doors open.
And speed is not a weak point. A tight C++ numerical loop compiled through Emscripten can be very fast. If I write cache-friendly code, avoid unnecessary allocation, and call into WebAssembly in batches instead of one point at a time, C++ can do the job well.
Where C++ makes me hesitate
The part I dislike is not modern C++ at its best. It is the boundary between browser code, raw memory, and old habits that C++ still permits.
My current C++ shape has a familiar WebAssembly export:
void sample_ground_grid_pa(
const ConcretePrism& prism,
const GroundDomain& ground,
double applied_load_n,
double sample_y_m,
double field_width_m,
double field_depth_m,
int columns,
int rows,
double* output_values_pa) {
if (!output_values_pa || columns <= 0 || rows <= 0) {
return;
}
const StressReport report = calculate_stress_report(prism, ground, applied_load_n);
for (int row_index = 0; row_index < rows; ++row_index) {
const double z_ratio =
rows > 1 ? static_cast<double>(row_index) / static_cast<double>(rows - 1) : 0.0;
const double z_m = field_depth_m * 0.5 - z_ratio * field_depth_m;
for (int column_index = 0; column_index < columns; ++column_index) {
const double x_ratio =
columns > 1
? static_cast<double>(column_index) / static_cast<double>(columns - 1)
: 0.0;
const double x_m = -field_width_m * 0.5 + x_ratio * field_width_m;
const int value_index = row_index * columns + column_index;
output_values_pa[value_index] =
calculate_stress_at_point_pa(prism, ground, report, x_m, sample_y_m, z_m);
}
}
}This is normal C++ WebAssembly code, but the contract is mostly in my head. Did the caller allocate enough values? Are the dimensions valid? Should invalid input return silently? Are the units right? If I later add more arrays for displacement, strain, or colour mapping, the exported function can become a long row of positional arguments and pointers.
Modern C++ can improve this with references, value types, standard containers, spans, and careful wrappers. But C++ cannot make old pointer logic disappear. The language has to keep enormous amounts of existing code valid, so it cannot simply decide that unsafe pointer patterns are no longer allowed by default.
That backwards compatibility is one of C++'s strengths, but it is also baggage. For a small browser teaching aid, I do not need that baggage unless I am buying access to an existing library that justifies it.
Why Rust fits the kind of code I am writing
Rust starts from a different default. Ownership, borrowing, slices, and result types push me to say what owns the data and what can mutate it. That is not academic for a physics demo. A wrong buffer length or a swapped unit can make a visualisation look plausible while being wrong.
I would probably split the Rust version into a pure calculation core and a thin WebAssembly wrapper. The core can stay ordinary Rust:
pub struct ElasticMaterial {
pub density_kg_m3: f64,
pub youngs_modulus_pa: f64,
pub poisson_ratio: f64,
}
pub struct ConcretePrism {
pub width_m: f64,
pub depth_m: f64,
pub height_m: f64,
pub material: ElasticMaterial,
}
pub struct GridSample {
pub sample_y_m: f64,
pub field_width_m: f64,
pub field_depth_m: f64,
pub columns: usize,
pub rows: usize,
}
pub fn sample_ground_grid_pa(
prism: &ConcretePrism,
ground: &GroundDomain,
applied_load_n: f64,
sample: GridSample,
output_values_pa: &mut [f64],
) -> Result<(), ModelError> {
let expected_len = sample.columns * sample.rows;
if output_values_pa.len() != expected_len {
return Err(ModelError::WrongOutputLength {
expected: expected_len,
actual: output_values_pa.len(),
});
}
let report = calculate_stress_report(prism, ground, applied_load_n)?;
for row_index in 0..sample.rows {
let z_ratio = if sample.rows > 1 {
row_index as f64 / (sample.rows - 1) as f64
} else {
0.0
};
let z_m = sample.field_depth_m * 0.5 - z_ratio * sample.field_depth_m;
for column_index in 0..sample.columns {
let x_ratio = if sample.columns > 1 {
column_index as f64 / (sample.columns - 1) as f64
} else {
0.0
};
let x_m = -sample.field_width_m * 0.5 + x_ratio * sample.field_width_m;
let value_index = row_index * sample.columns + column_index;
output_values_pa[value_index] =
calculate_stress_at_point_pa(prism, ground, &report, x_m, sample.sample_y_m, z_m)?;
}
}
Ok(())
}The important difference is not that this Rust snippet is shorter. It is that the failure modes are harder to ignore. The output length is checked. Invalid dimensions can return a typed error. The mutable buffer is a slice, not a naked pointer. I can still optimise later, but I begin with a safer shape.
For the browser layer, wasm-bindgen gives Rust a practical way to talk to JavaScript with richer types than bare numbers. For small teaching grids I could return a vector and let the wrapper copy it into JavaScript. For larger grids I would keep a reusable buffer and expose it as a typed array. Either way, I want the unsafe boundary to be thin.
Rust is not free
Rust has its own cost. I have to learn the borrow checker properly, choose crates carefully, and accept that some numerical or engineering libraries are less established than their C++ equivalents. If I need a very specific solver that already exists in C++, rewriting it in Rust would be wasteful.
The WebAssembly target also has limits. The Rust compiler documentation for the browser-style WebAssembly target is explicit that parts of the standard library do not behave like a normal operating system. File access, threads, and printing need browser-aware design. That is fine for my teaching aid, but I should not pretend it is the same as a native executable.
There is also glue code. Rust plus wasm-bindgen is pleasant, but it can add generated JavaScript and packaging steps. C++ plus Emscripten has its own glue. In both cases, I need to measure the actual output instead of trusting language marketing.
Performance is not where I would start the argument
For this kind of code, I would not assume C++ is automatically faster or that Rust is automatically safer in the final product. I would benchmark the shape I actually ship.
The expensive mistakes are likely to be language-independent:
- calling WebAssembly once per grid point instead of sampling the whole plane in one call
- copying large arrays between JavaScript and WebAssembly too often
- allocating inside inner loops
- using expensive math functions where simple multiplication would do
- building a grid that is visually denser than the browser can present usefully
Both languages can produce fast numeric WebAssembly. Both can use optimisations such as SIMD Acronym Single instruction, multiple data. A processor technique where one instruction operates on several values at once, often useful in numeric loops, physics, graphics, and image processing. when the browser and compiler settings support it. Both can become slow if I design the boundary badly.
For a teaching aid, I would measure four things before making a final call:
- download size after release optimisation and compression
- time to calculate a typical grid, such as 80 by 80 or 160 by 160 samples
- time spent crossing the JavaScript and WebAssembly boundary
- how hard it is to add the next bit of physics without making the code brittle
The Rust WebAssembly page makes a good case for small code size and predictable performance, but I would still verify it with my own calculation. A browser demo is judged by load time and interaction feel, not by a language scoreboard.
How I would migrate the current C++ idea
I would not throw the C++ version away immediately. I would keep it as a reference implementation and port the model in small pieces.
- Keep the C++ output for a few fixed scenarios.
- Write the Rust structs and pure calculation functions.
- Assert that Rust and C++ produce the same stress values for the same inputs.
- Move the browser visualisation to call the Rust build only after the numbers match.
- Benchmark both versions with the same grid sizes and browser hardware.
That gives me a practical comparison instead of a philosophical one. If the Rust version is close in speed, smaller or similar in size, and easier to extend, I would move. If C++ wins clearly because of a library I need, I would stay.
My current decision
For this civil engineering teaching aid, I am leaning Rust. The problem is small enough that I am not locked into a C++ library, and correctness matters more than squeezing out a theoretical micro-optimisation. Rust lets me model the calculation with safer defaults and keep the browser boundary narrow.
I still respect C++ here. It has better library reach, a bigger employment market, and a proven WebAssembly toolchain. If I were building around an existing C++ solver, I would not rewrite it just to feel modern.
But for my own browser physics code, starting fresh, Rust looks like the better long-term fit. It gives me enough performance, better pressure toward safe data handling, and a clearer path from learning experiment to teaching tool.
That matches how I increasingly think about software: use the boring established option when it buys real leverage, but do not inherit legacy complexity just because it is available. I wrote about a related instinct in writing more code myself instead of adding dependencies.