Abstraction is great until I need a rollback
Nikos Katsikanis - April 28, 2026
I like infrastructure abstractions when they buy me speed, but I do not want them to become the operating model for a production system that needs exact rollback, ownership, and recovery control.
There is a class of infrastructure tooling that feels excellent on day one.
I point it at a codebase, define a few routes, maybe add a table or two, and suddenly I have a working AWSAcronymAmazon Web Services. I use AWS to mean Amazon’s cloud platform for compute, storage, networking, databases, deployment, and managed infrastructure services. application without thinking too deeply about Lambda packaging, Amazon APIAcronymApplication programming interface. I use API to mean a defined software boundary that lets one system call or integrate with another system. Gateway wiring, IAMAcronymIdentity and access management. The systems and policies used to define who can access what and under which conditions., CloudFront, deployment buckets, or stack orchestration. For prototypes and small internal tools, that can be a real win. It compresses the time between idea and deployment.
The problem is that production systems do not stay day-one simple.
At some point my question stops being “can I deploy this?” and becomes “can I operate this safely when it breaks?” That is where high-level infrastructure abstractions can stop helping and start getting in the way.
This is not an argument against abstraction itself. Every non-trivial system uses abstraction. The problem is using an abstraction layer as the primary operating model after the system has outgrown the assumptions that abstraction was built around.
Simple deploys can hide split releases
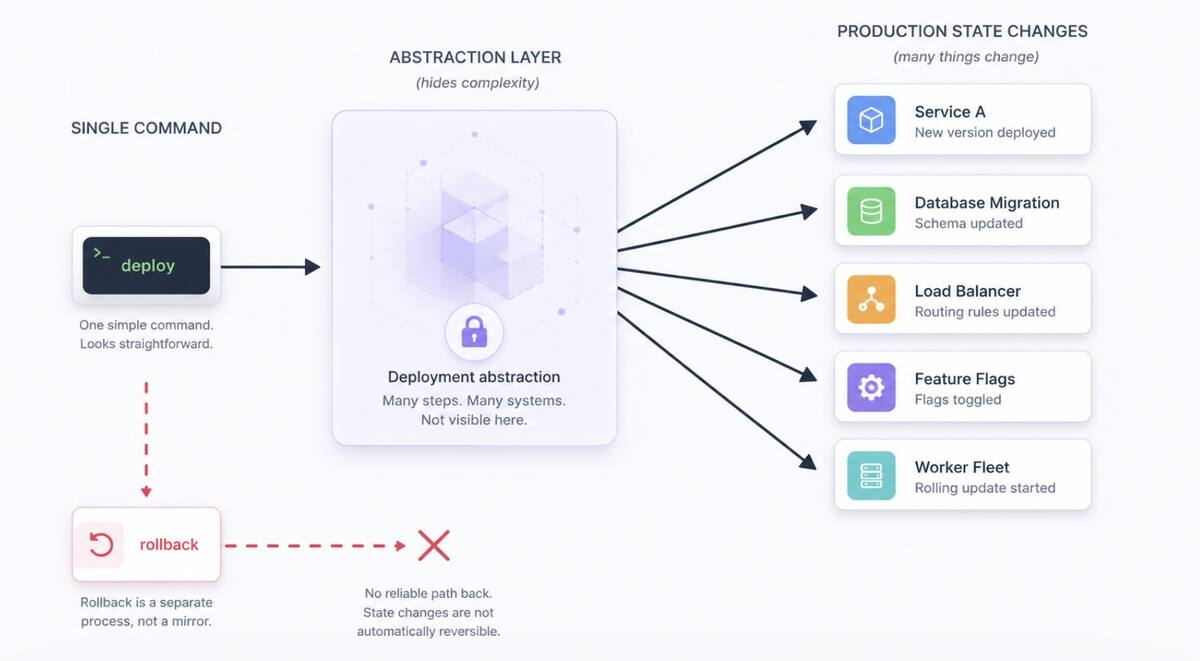
In one application I worked on, the deployment model looked simple on paper. A single command updated the server runtime. Static assets were synced separately to S3AcronymSimple Storage Service. I use S3 to mean Amazon’s object storage service, often used for static assets, uploads, backups, and deployment artifacts.. A CDNAcronymContent delivery network. I use CDN to mean globally distributed edge infrastructure that caches and serves content closer to users. invalidation pushed the new version globally. The workflow was easy to understand when everything was healthy.
But that simplicity was misleading. The deploy was not really one atomic release. It was several separate state changes that had to line up correctly: application code, environment variables, static assets, CDN state, and additional infrastructure managed elsewhere.
If production broke halfway through or immediately after deploy, there was no real rollback button. There was only a sequence of manual recovery steps.
That is the hidden cost of a lot of high-level infrastructure frameworks. They remove visible complexity early by hiding operational complexity until later.
Production needs hard guarantees
A serious production system eventually needs a few guarantees that are hard to fake.
- I need a tested artifact that can move unchanged from one environment to another.
- I need a rollback process that is not “rebuild an older commit and hope the result matches what used to be live.”
- I need explicit resource ownership so I know which layer controls a bucket policy, a Lambda runtime, an IAM permission, or a table definition.
- I need infrastructure changes and application changes to be independently understandable, and sometimes independently deployable.
- I need observability built around the real runtime, not around whatever subset the abstraction layer exposes cleanly.
That is where high-level abstractions start to fail serious applications.
Failure mode 1: deploy opacity
When a framework turns deployment into one pleasant command, it can also collapse important distinctions.
Was this an application deploy or an infrastructure deploy? Did it replace a function, mutate environment variables, republish assets, recreate permissions, or all of those at once? If something went wrong, what exact thing changed?
If I cannot answer those questions quickly during an incident, the abstraction is no longer reducing complexity. It is delaying my access to it.
I wrote more optimistically about this style of tooling in Why I use Architect for AWS development. I still believe tools like that can be valuable. The point here is the boundary: the same convenience that is useful early can become too opaque once rollback and ownership matter more than setup speed.
Failure mode 2: rollback theater
A lot of tools make deployment easy but do not make rollback a first-class primitive. That is a warning sign.
In production, rollback is not a nice-to-have. It is part of the deploy design. If the release model is “update things in place” and the recovery model is “run the old deploy again,” I do not really have rollback. I have a second forward deploy pointed at older code.
Those are not equivalent.
The distinction becomes painful when static assets are versioned one way, server code another way, and CDN state a third way. A safe rollback needs all of those pieces tied to the same release identity. Many abstraction layers never force me to model that explicitly, so the gap stays hidden until an incident exposes it.
Failure mode 3: blurred ownership
As systems mature, I usually want clearer boundaries. I may want some infrastructure defined in a general-purpose IaCAcronymInfrastructure as code. I use IaC to mean defining cloud resources in reviewable files instead of relying only on manual console changes. tool, some application runtime behavior managed separately, and some legacy pieces left alone until migration is worth the risk.
That transitional state is normal. But abstraction-heavy frameworks often assume they are the center of the universe. They do not naturally encourage partial ownership models.
The result is an awkward compromise: one system manages the app runtime, another manages newer data resources, and the seam between them becomes the most fragile part of the platform.
Failure mode 4: escape-hatch economics
Supporters of these frameworks often say, correctly, that I can always drop down to raw AWS when needed.
That sounds fine until I do it repeatedly. Once I have enough exceptions, overrides, custom scripts, post-deploy checks, manual policy stitching, and special-case resource ownership, I am no longer benefiting from a clean abstraction.
I am paying the cognitive cost of both layers at once: the underlying cloud platform and the abstraction framework sitting on top of it.
That is the worst operating point. I still have less direct control than raw infrastructure, but I no longer have the simplicity that justified the abstraction in the first place.
Creation and controlled change are different problems
The deeper engineering issue is that abstraction layers often optimize for initial creation, while serious systems optimize for controlled change.
Those are not the same problem.
Creating a Lambda, a route, and a table is easier than answering these questions:
- Can I promote the exact artifact that passed staging into production?
- Can I roll back in under two minutes without rebuilding anything?
- Can I deploy app code without unintentionally changing infrastructure?
- Can I change infrastructure without redeploying the app?
- Can I see, in plain AWS terms, what owns each resource?
- Can another engineer debug a production incident without first learning my framework’s internal mental model?
Those are the questions that separate toy-scale convenience from production-grade operations.
Where I draw the line
I do not think teams should never use high-level infrastructure tooling. My conclusion is narrower and more useful.
Use abstractions aggressively when they buy speed. Stop deepening them once operational needs exceed their model. Be honest when the tool becomes a liability.
A lot of teams stay too long because migration feels expensive. That instinct is understandable, but it often creates the worst possible outcome: a business-critical system whose runtime behavior depends on a framework that no longer matches how the team needs to deploy, recover, observe, or evolve the system.
The better path is usually gradual containment. Keep the old abstraction stable. Stop adding new critical responsibilities to it. Move new infrastructure into explicit, reviewable definitions. Introduce immutable release artifacts. Make rollback a designed workflow, not a panic procedure.
Over time, shift the center of gravity toward infrastructure I can reason about directly.
The real lesson
The danger of high-level infrastructure abstractions is not that they are simplistic. It is that they make serious systems look simpler than they are, right up until operational reality demands exact control.
On that day, the abstraction layer does not remove complexity.
It hands it back all at once.